


TL;DR Solution that are both quick & easy to apply are usually a clear win, but in case of using cache to "fix" performance issues it may get really deceptive. Cache is a good tool (if applied correctly), but the concept of caching scales very poorly with increasing both distribution & domain complexity, UNLESS you follow some very basic rules that may be very restrictive, but help with saving the composition & state coherence within the system.
One can divide software systems into two performance-related categories:
- ones for which performance is not only absolutely crucial, but also its variability tolerance is very low, so it's always the top of the list concern for engineers working on them (e.g. trading systems, b2c global retailers in highly competitive markets, real-time systems of various sorts)
- the rest :D
Fortunately (?) "the rest" is an overwhelming majority, but that has caused an interesting effect - a huge gap in terms of awareness, experience & palette of optimizing skills between engineers who work on these two categories. Specifically, the latter group seems to have just one, universal answer to any performance-related issue: caching.
"Solution"
Caching is not bad per se, it's one of the techniques that definitely have its applicability in certain scenarios, but I can't help the impression that it's not only over-used, but what is worse:
- it frequently covers the problems (& hides them "below"), instead of solving them (if you're calling a remote function 100 times it may save a lot of time to cache its result, but why are you calling it 100 times anyway? maybe there's a far more elementary problem beneath anyway?)
- cache that gets out of strict control / governance causes more harm than good, e.g. by loosening the cohesion (updated data mixed with cached data, non-deterministic queries, pseudo-commits on cache with delayed server synchronization, etc.)
- once cache gets its own purpose-specific structure, it may drift far off enough to get its own in-memory life-cycle, adding another layer of abstraction & complexity; in some cases in may be fully intended & justified, but in other cases it may wreak havoc & destruction
Why do devs favor caching over getting to the root cause of encountered issue(s)?
Caching makes the "solution" more local, hence limiting the regression scope. Dev doesn't have to get her/his hands dirty in code that may be someone else's, may be legacy, or may be just too fragile to deal with in a safe manner. Cache is usually creating something new, a new, "clean" layer of abstraction. What is more, caches are usually memory-based (and memory is - in general - cheap), so they are quite a safe bet - even if cache is designed poorly or inefficiently, negative consequences won't be visible immediately, at least the performance-related ones. And the model-related (or composition-related) ones are usually highly underestimated.
Stash it like a boss
These problems are not something that can't be tackled with proper approach & attitude. The important thing is to follow some general rules to keep caching sane & trouble-less:
- service consumers should not know about cache, shouldn't have an explicit option to use cache - consumer utilizes some sort of service, depends on its contract & shouldn't care / know about technical aspects (implementation details) like caching
- access to particular piece of data / service should be uniform & singular (as one end-point) - cache should be hidden within (primary) service that acts as a single point of contact
- transparency of cache is not only about querying it, but also about its retention management & invalidation in particular -> these should be "embedded" in the "bowels" & not controlled by the consumer explicitly; that's why caching strategy shouldn't be tuned just for access frequency, but also for access type - e.g. applying caching for immutable or lowly volatile data is far easier, while potentially still very beneficial
- an approach to cache scaling & synchronization should preferably be considered & designed up-front: these aspects may easily increase the complexity of the solution tenfold; the golden rule is simple: avoid (distributing cache) if you can
- the faster you verify you assumptions regarding cache, the better - cache that doesn't get any hits on production is nothing more than pathetic ...
Key rules from above can be easily illustrated with the diagrams. Let's start with a simplified perspective of a sample system that doesn't provide caching:
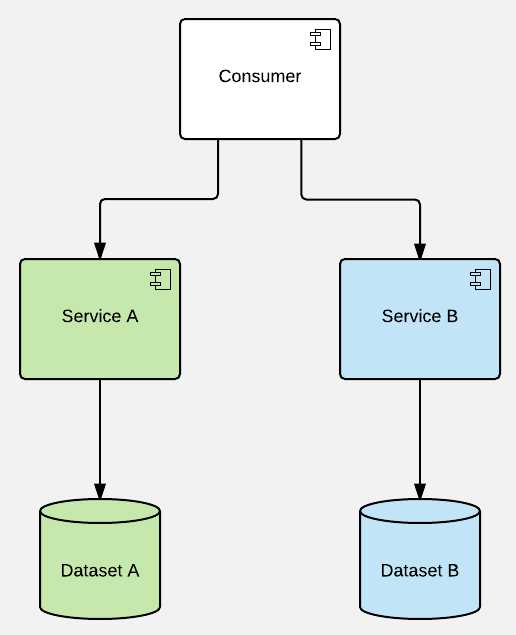
Here'd be a solution I find "the most broken", as it leaves the decision on whether to use cache or not to the service consumer (whether cached content is persistent or not is not really relevant):
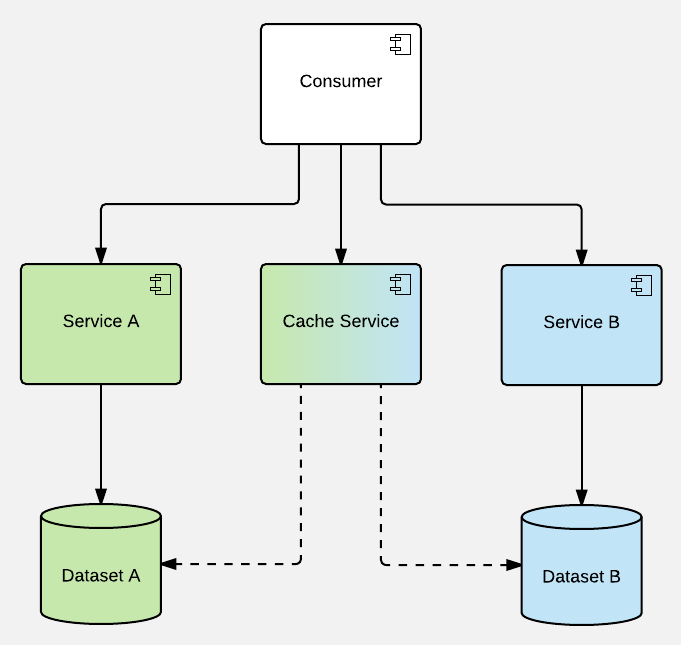
It gets only very slightly better if you're caching processed (transformed) data on consumer's side & you manage the mixed cache state (usually view models) manually there. This gets ESPECIALLY troublesome if applied independently throughout several layers (consumers serving as another level providers, etc.), just imagine the troubleshooting over several layers of abstraction, each one with its own ephemeral state:
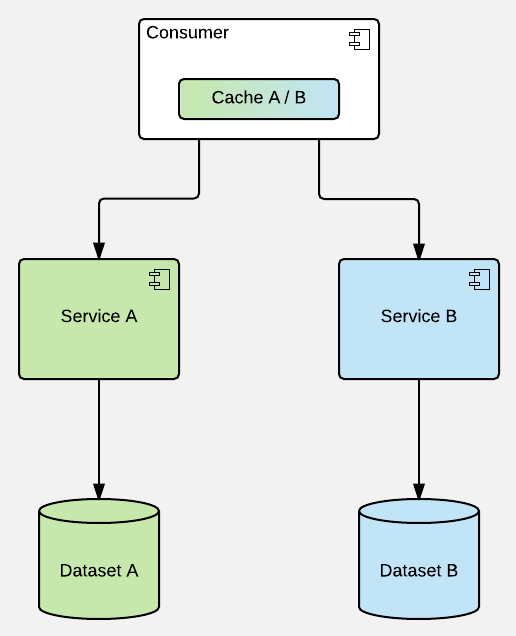
Caching on consumers (preferably just the final one in processing chain) is not too be condemned per se if all the service access goes via corresponding cache (just like in state managers of modern web applications) - disciplined approach to that is sometimes called an isomorphic API & has its sensible use cases.
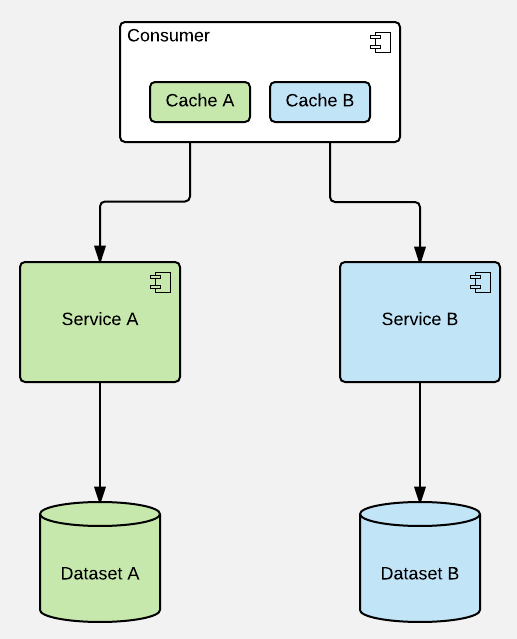
But the most maintainable (& scalable, & composable, etc.) solution (not necessarily the best performing though!) would be to leave caching to services (even if it means redundant round-trips) - they supposedly are the most capable in terms of caring for proper data (& cache) life-cycle management:
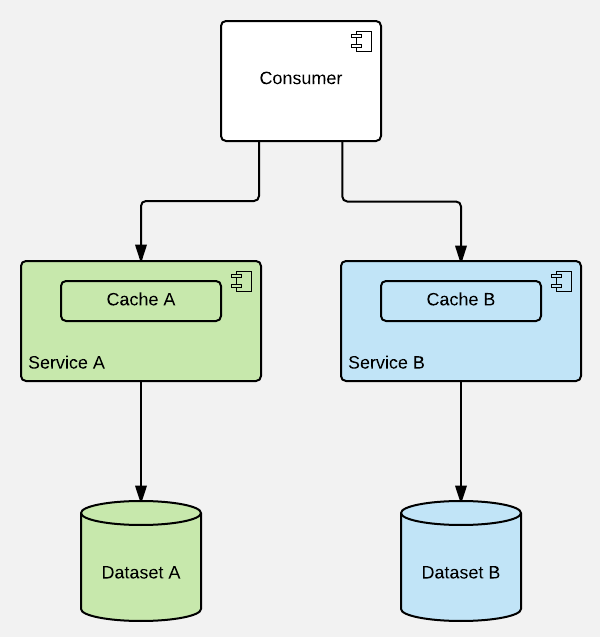
This model can be extended to multi-layer variant as well, but I wouldn't advice that. Speeding up memory with another chunk of memory rarely makes any sense & horizontal synchronization of different caches (e.g. built for different API gateways) may be a huge pain in the neck.
Pic: © monsitj - Fotolia.com





