


This blog post is all about ... reducing risk versus narrowing ground zero area, operability, what does it mean that software should be built like ship hulls, that resilience analysis doesn't start with deployment units, how well-designed systems are prepared for partial failures & why GD has to be very simple.
General engineers' awareness regarding high availability has massively improved over last few years. Redundancy, load-balancing, self-healing, multi-replica DBs, auto-scaling groups - all that sort of stuff is bread'n'butter these days. Which is good (unless you don't need HA, but it's a different kind of story ...).
We do a lot to reduce the chance that our services are down, a bit forgetting that it will eventually happen - yes, it's good to reduce the risk, no doubt about that, but the cost to guarantee another, consecutive '9' of availability grows very steeply.
That's why today I'd like to focus on something different - not reducing the risk of failure, but reducing its impact - this is widely known as Graceful Degradation.
My (simplified) definition is as follows:
Graceful Degradation (GD) is all about platform's resilience. Partial (point) failures have to be isolated to provide as much of remaining functionality as possible with a single purpose in mind - assure that users'/clients' operability remains as little affected as possible.
Operability is an ability to fulfil standard everyday duties ("business as usual") - to service the clients: keep the revenue flowing in, possibly even enable new users to register/on-board, etc. (whatever the activities to preserve business continuity are).
So as you can imagine - GD is all about resilience (of the whole system/platform/application) & bulk-heading (making sure that if one of ship hull's section is leaking, other ones remain unaffected).
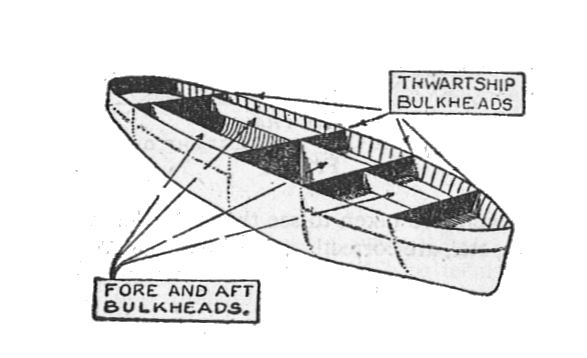
You design & plan while assuming that shit has already hit the fan & now you're trying to save as much as possible (not in terms of recovery but uninterrupted service continuity - these are different stories!). Btw. if you don't plan for GD up-front (so your architecture doesn't support it by design), at some point re-introducing it will be VERY expensive.
GD 101
Neat. How do you start then?
With collecting business/domain knowledge. The first step is to understand the functional architecture of what you're building/working on:
- what are the key functionalities/processes (grouped in coherent & closely related chunks)?
- what are the dependencies between them?
- which ones are absolutely critical for clients'/users' business operations, which can be worked around temporarily, the absence of which will be just annoying or maybe even not perceptible by an average user?
- in which case(s) read-only access is good enough (at least temporarily) & where write-access is absolutely critical?
- for read-only data (of particular functionality/module) - what's the accepted data freshness (max. difference between latest sync & read time)?
- for write-enabled data - is it OK to (again - temporarily) just collect user input & process it later (once full operations are restored) or do potential data clashes (conflicts) or complex validations make that impossible?
Answers to these questions make you able to craft some sort of functional map that divides your system/platform into separate functional areas of different "criticality" & different expectations regarding availability.
Now the hard part begins - you need to cast this map upon the solution architecture of your system's components (both component & deployment one) - because these are the ones that will eventually break (have errors, be too slow, go offline, etc.).
GD in the wild
In poorly designed (or rather: not designed or "designed by accident" ;P) systems this exercise usually seems to lead to nowhere ... Everything is dependent of everything, functional areas are not distinguishable in the code at all, technical components do not correspond to how business works (processes, revenue streams, even whole bounded contexts).
OTOH in well designed systems ...
- model corresponds directly to code (so the scope & consequences of failure are predictable, if not fully clear)
- functional modules (capabilities) communicate via well-designed API, so you control "junction points" & can easily control behaviour when the well-separated dependency goes off-line
- it's possible to disable modules even on the go (doesn't have to be automated, manual is good enough as long as it propagates automatically across the run-time processes)
- UI is prepared (by design) for partial failures
- there may be even a hot-swappable bare minimum service level version of the system (e.g. independent read-only access, functionally stripped replica) to be used in case of catastrophic failure - independently deployable (in terms of both tools/config & time of deployment)
In real-life you're probably somewhere between good & shitty design.
Which probably means you have to aim for lower level of component granularity (split everything into 2-3 coupled groups: "critical" + "important" + "whateva") and/or have a global flag that disables write access for the whole platform (reserved for suspected data corruption).
And that's not a tragedy yet. It's very easy to "over-sophisticate" your GD mechanism, while the goal is exactly the opposite: it has to be very simple to make sure it doesn't fail when it's needed (as the sky is already falling by then ...). I seriously encourage you to think about it up-front, having such a fallback route catapults you instantly (using ITIL terms) from incident handling heat to problem solving routine which is a completely different level of stress & end-users' frustration.
