


This blog post is all about: the definition of what Model Debt is (& what isn't), how is it created (& why), how to avoid growing Model Debt, whether Model Debt does have anything in common with Technical Debt (& can one use technology to fix it).
Disclaimer #1: I was considering writing this post for some time already (as another step in my "Fiber-Driven Development" observations), but the final "trigger" to finally give it a go was attending "Technical debt isn't technical" by Einar W. Høst (at DDD Europe 2019) - I think the author has made a tremendous job to nail down the concept. Video from this conference is not available yet, but you can watch the same session performed at the different stage here. No worries, I'm not gonna xero Einar, but approach the topic from a bit different perspective.
Disclaimer #2: Includes sarcasm. Use with caution.
What's a Model Debt?
One of the best definitions are "by-example" ones. Let's try this approach:
A Product Owner approaches you with a simple idea - a tiny extension, adjustment that is expressed in just one paragraph of "business language". Not something completely new but a new variant, related to abstractions & concepts already present in the solution. Yet, shockingly you come up with a realization that implementing this single thing will require the team to:
- "refactor" half of business logic
- pepper whole solution with myriad of if statements to separate "standard" processing from the new "paths"
- turn upside down the big part of the data model
You wonder in amazement - how did it happen? Technical quality is undisputed! Automated tests are here, so are SRP, DRY, SOLID principles ... Everything has been hexagonised, CQRS-ed, turned reactive & async with swarms of domain events. All micro-services ain't bigger than X LoC - even Uncle Bob would be proud!
What has failed then? Why is this change such expensive and why does it ... break our beautiful architecture?!
OK, back to reality - what has REALLY happened here?
Real-life (/domain) problems rarely turn completely upside down within a day. For several reasons: operational inertia (organization has to change to adopt software change), needs & expectations (of end-users) do not change overnight, radical changes cause cascades of changes in dependencies (to grok through), etc.
Real-life solutions are built upon foundation of "core" concepts & abstractions (which are supposed to be parts of UL - Ubiquitous Language). Changes & adjustments are also about them - they enhance, enrich, fork & do a lot of different stuff to them.
Legend:
- pink cards are all sources of inbound continuous envisioning & inspiration input - unruly, unstructured, not necessarily fully controlled :)
- blue cards are conceptual models IN PEOPLE HEADS, it's how they see solution in terms of what is most important TO THEM and using the means of abstractions THEY KNOW (& are skillful with)
- green cards are artifacts - these are not in heads but written down, scribed, recorded or documented in aaaany way (yes, code is an artifact as well)
Here's what happens in a typical, "fiber-based" development process:
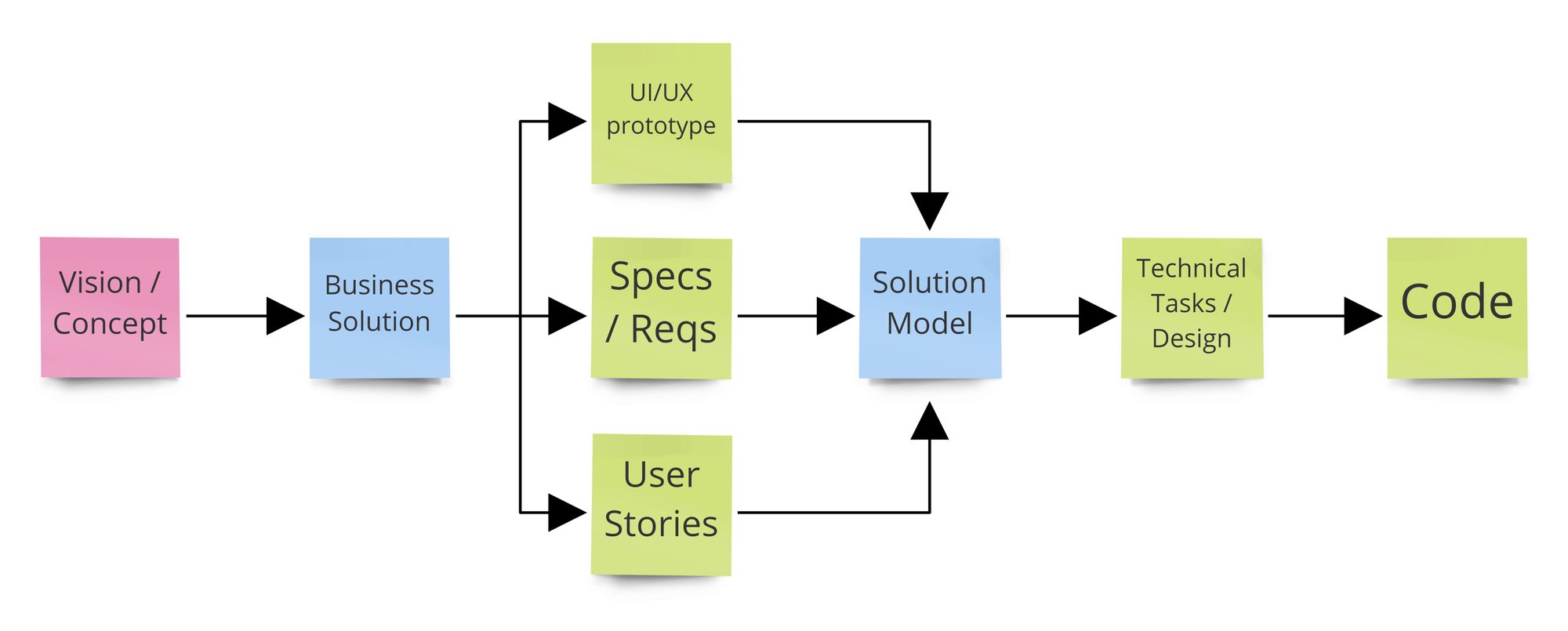
Step 1: Business Solution
Business Solution is formed IN THE HEADS of "business people" (business stakeholders, product owners/managers) - they know what they want to achieve, they understand their way - even if it's written down, it's very "internal" - smeared around business cases, PPTX presentations, strategies, etc. They are not bothered with that, this is enough to both: share the understanding between themselves (people thinking likewise) and integrate this solution with all the other work they do on daily basis.
Step 2: Mapping to artifacts
To get it done (as an IT service/app/system) they need to turn it into artifacts expected (/required!) by IT industry: either themselves or with help of IT people - such like UI/UX prototypes, Specs/Requirements, User Stories. This effort is mainly "mapping" the vision in their heads into something validable from end-users perspective (because the "bowels" of software are too ephemeral for them), usable, interact-able.
BUT! When they think about it in their heads, they DON'T think in requirement rules or user stories. Neither of these artifacts directly represents the INTENT, the BIG PICTURE on higher level of abstractions. In fact - frequently "bigger concepts" have to be shredded into smaller & simplified ones because of YAGNI or to fit stuff within Sprint. This is why this mapping & "compression" is usually NOT LOSSLESS (some knowledge is lost "in translation") - like making a 2D picture of 3D reality - it represents a segment of a scene, but only the visible parts, with limited information about what's behind & how deep is the scene ...
Step 3: Reverse-engineering
Wait, we're not done yet. Engineers read these artifacts and ... to understand what they are suppose to create, they reverse-engineer them in their heads to "rebuilt" the joint Solution Model. To understand the intent, purpose, constraints & separate parts that are supposed to be flexible & extendable from those that are domain invariants & parts of the foundation. But reverse-engineering from a product of non-lossless mapping is NOT guaranteed to produce something 1:1 congruent with Business Solution.
Step 4: Obvious "obviosities"
The rest of the flow is obvious & "boring". It's the Solution Model (not Business Model) that gets turned into technical workitems & implemented. Freaking Chinese whispers, don't you think?
Rinse & repeat
Keep in mind that this is not a single-time flow. Each change (of existing system) is another run through the cycle: Business people adjust their Business Solution (using terms & abstractions specific for BS), map these changes into artifacts (another lossy transformation ...) which are reverse-engineered into changes to existing Solution Model.
FINALLY, ...
... we've got down to the root of the problem.
(yes, this is supposed to be your "a-ha" moment ...)
The further Solution Model has drifted from Business Solution, the harder to reverse-engineer these adjustments. If "abstractions" in both conceptual models do not map 1:1, it will get incrementally harder & harder to reflect changes in one model into another. And this will (never) improve in time w/o deep re-modeling.
This "skew", "drift", "discrepancy" is what I call a Model Debt.
The tiny adjustments to Solution Model (based on reverse-engineering of artifacts) I call Fibers.
As you can see, Model Debt has NOTHING in common with Technical Debt. But it can be equally as dangerous (if not more). Why so?
You've got the answer in the example at the top of the post - Solution Model with Model Debt is not "future-proof". Well, nothing is fully future-proof, but the cost of "natural" (oriented around key abstractions) changes that are just adjustments of Business Solution are totally unpredictable & usually skyrocket in Solution Model. This extremely slows down the development & introduces shit-loads of accidental complexity applied to "patch" botched model.
Avoiding Model Debt ...
... is actually quite simple & if you know anything about DDD, you should already have all the pieces in hand. Now it's "only" about understanding their role & how they "fit together".
OK, let's fix the picture first.
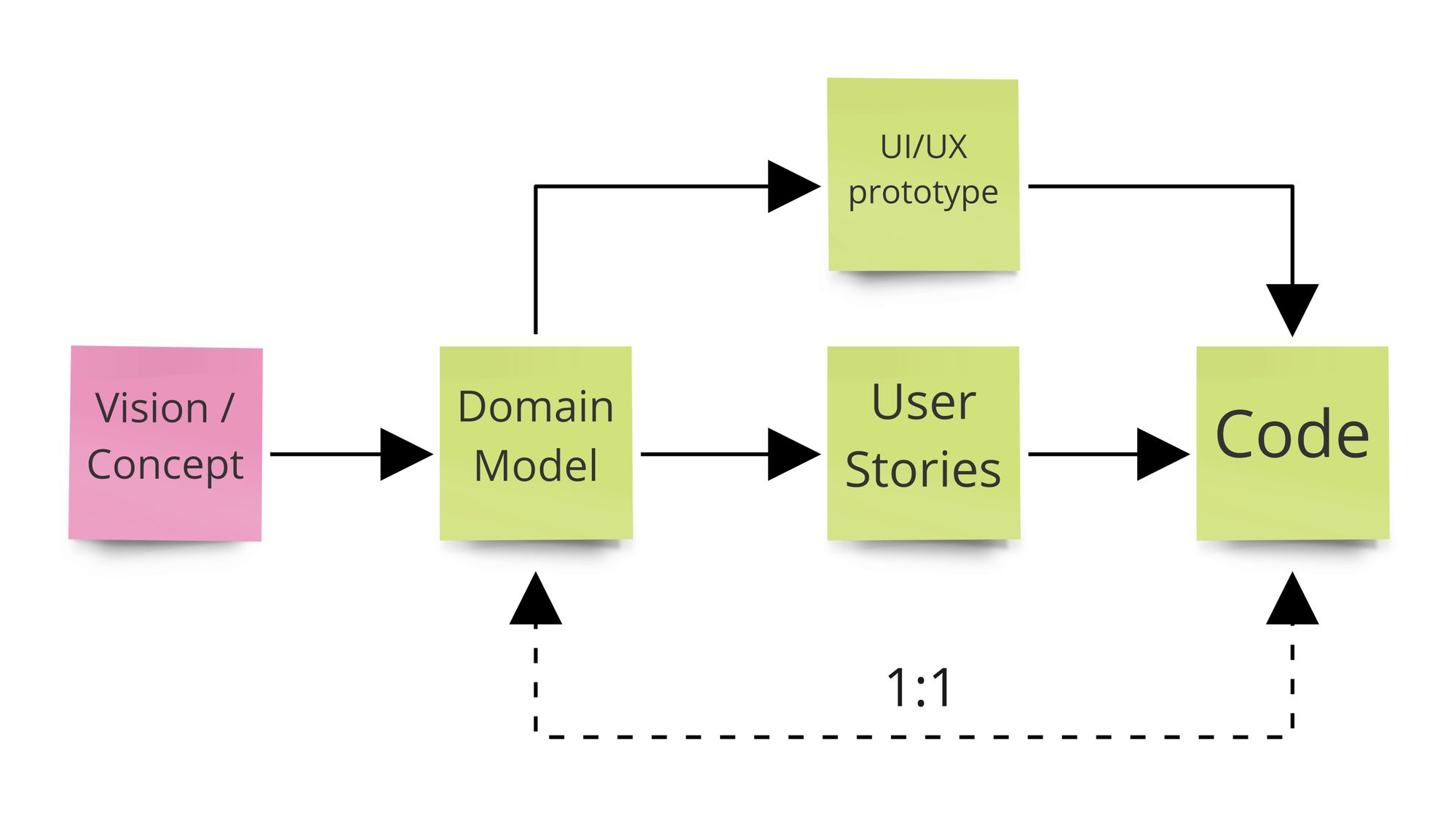
It's the same flow, yet somehow simplified. Artifacts are still there (at least these that make some sense) because the key difference is somewhere else:
- Business Solution & Solution Model have been unified (as a Domain Model)
- There's a 1:1 correspondence line between Domain Model & Code
This is real-life, practical application of the most basic DDD principles:
- Parts of the Domain relevant to problems you're facing are reflected in Domain Model, which is shared between everyone working on the solution - starting with so-called "business people", ending with software engineers of all flavors
- There's just ONE Domain Model, described in Ubiquitous Language - used in all conversations AND in artifacts like code or tests
- Long-term correspondence between code contracts & model is essential - it helps us to avoid aforementioned sins like: lossy mapping & half-blind re-verse engineering of obscure "business" models
- Artifacts like User Stories or UI/UX Design are just supplements & aids to help with either organizing the work (the former) or polishing interactions with users (the latter)
There are TWO crucial thinks to focus on if you want to succeed with these points:
- Build your UL abstractions directly INTO your code: instead of creating new tech abstractions (managers, handlers, event stores, adapters, facades, ...), introduce ones known from your UL - specific to your model/UL. If some abstractions are mentioned in modeling conversations you should ALWAYS be able to locate those abstraction (with what it contains: logic, data) in your code. And vice versa.
- Don't ignore new terms popping up. You may think it's "just X, but with a new property Y set to Z", but this may be over-generalizing & assuming too much (looking for OO-style inheritance where it's not present, because surprise - RL doesn't give a shit about polymorphism ;P). Even if 2 abstractions share 95% of information it doesn't mean they should be put in the same conceptual bag - their purpose (the concern they address), life-cycle, applicability & domain invariants may be very different & surprisingly separate.
Final word(s)
Design should never be accidental (keep in mind that "evolutionary" has nothing in common with "accidental"!).
Trying to express sophisticated business changes with botched (non-adequate, built upon poorly-understood abstractions) model is like trying to use incorrect tools for the job: e.g. surgical instruments in psychiatry or cutlery in fencing. They seem related and shared some basic properties, bah - with enough effort you'll get some results (yikes!), but next time you re-visit this problem area the unit cost of change will be even higher.
If it already exists, can a Model Debt be reduced without "touching" technical stuff (e.g. data model)? Not likely. In the end Model Debt is implemented using the technology. What won't work for sure is starting to fix Model Debt with technical changes ONLY - in such case you seriously need to know where you're going FIRST.
Good luck.





